
Text Messages Sentiment Analysis

Introduction
Personal communications have always been a research-rich resource. Theodore Roosevelt’s journal and correspondence have been studied by historians, the FBI wants a backdoor into iPhones, even metadata about our phone calls are extremely valuable to the intelligence community.
Sentiment analysis is a method used to study the subjectivity of collections of text. It can be used in a variety of applications from analyzing song lyrics, to product reviews, to assessing public opinion through trends on Twitter.
In this project, I am turning the magnifying glass on myself and analyzing two years’ worth of text messages from my ten largest conversations. The primary goal is to do an overall sentiment analysis on the corpus and understand whether my conversations have tended towards positivity or negativity. I will also analyze how conversations with my wife compare to those with my friends.
Preparing the Data
Apple makes it difficult to extract large quantities of text from Messages into a format that is suitable for mining. It is not possible to simply export years’ worth of conversations directly from the application, it will only export the most recently loaded messages. The easiest way to export full conversation histories is to use a different messaging utility.
Since I worked at an Apple device management software company for years, I had experience with getting around a lot of the ways that Apple locks down their devices. Adium is a third-party chat application that can read message history from a Mac with some minor manipulation.
First, I needed to find the local storage directory of Messages. On Macs, this is in /Library/Messages by default. To ensure that I did not corrupt all my conversations, I made a copy in another local directory.
Adium can import chat history from a number of different messaging services, although it technically does not import directly from Apple’s Messages. To work around this, the copied Messages directory can be renamed iChat. Adium can then be pointed at the iChat directory and it will convert all of the messages therein to a format that it can use.
Next, I exported conversation histories from 2017 to present to PDF. This generated some large PDF files, up to 1GB in the case of the chat history with my wife. The documents included image files, screenshots of videos, and in addition to still not being txt files were going to need additional cleanup once converted again.

The dates, times, and sender data all needed to be trimmed out in addition to all of the standard word preparation necessary for analysis.
To get the PDFs converted to txt at a large scale with easy manipulability, I turned to the JavaScript and the xpdf library.
Once the PDFs were converted, I had to clean up a significant amount of noise and useless metadata from the files. This was a manual process via Sublime Text.
Data and Variables
There are 11 separate conversations that will be under analysis, however the group conversation for “Cool Dudes” had a fluctuating number of members and so was broken into three separate conversations in the Messages history. I will analyze each one separately, but also include a 12th conversation that is an aggregate of the three Cool Dudes conversations.
The positive words list that was used for analysis was compiled by Bing Liu, et al.
Analysis
When the text files were cleaned, I loaded them into a corpus in R for analysis. The data was tidied up a little further, such as removing stop words, to facilitate better processing and then assessed.
The sentiment function compared each word against a positive and negative word list. If a given word matched in either of those lists, the associated sum of positive or negative words was incremented. Then, the sum of negative words was subtracted from the sum of positive words. If the resulting value was a negative number, then the overall sentiment of the text was more negative than positive. The same holds for a resulting positive value.
A higher magnitude of the resulting value indicates that the text is more positive or more negative but this number cannot be directly compared across between documents without performing some normalization. To understand how our overall conversations compared in overall tone, simply divided the resulting sentiment score by the number of words in the text.
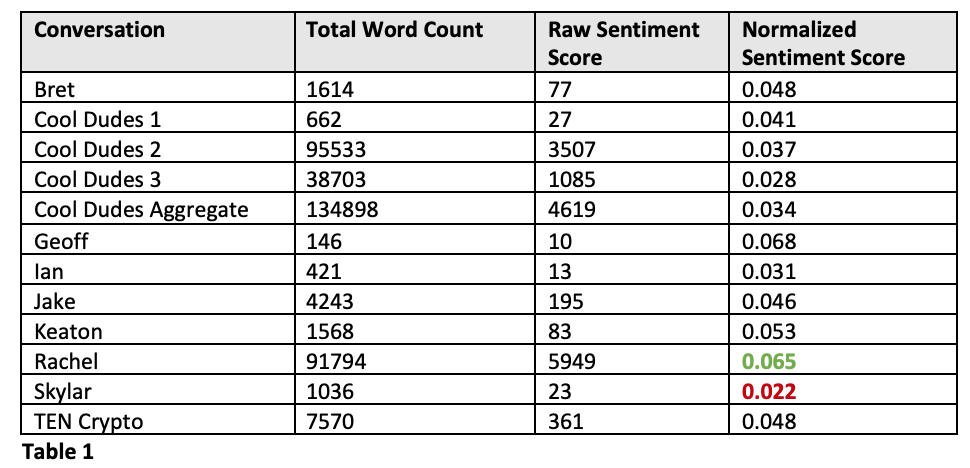
Table 1
Note, I also ran the analysis without removing English stop words first and that produced wildly different results. There must be one or more stopwords in the tm_map English stopword list that is also in the negative-word-list.txt. Further analysis should be done to determine which word(s) are involved and whether they should actually “count” towards the negative sentiment score.
Table 2 shows results without stopwords removed.
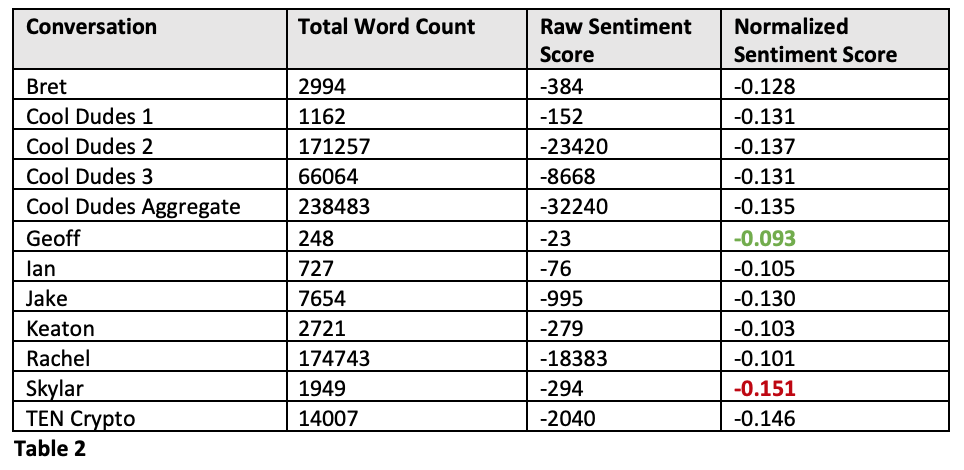
Table 2
Clearly the inclusion of the stopwords completely changes the sentiment of all conversations. The first execution resulted in strictly positive sentiment scores, while the second flipped all scores to not only negative, but also with a much higher magnitude.
Since the execution that included stopwords includes all of the recommended data cleaning methodologies, we will treat that as the true sentiment of the messages. It is surprising to me that all of the conversations received a positive score. The group chats that my friends and I have are often exceptionally negative, or seems that way.
There are a couple of reasons that we may see the positive score, though. First, the stopwords list could include a negative word that we use a lot. Alternatively, a lot of the negativity could be sarcasm and use positive words to express negative sentiment.
Conclusion and Further Research
In conclusion, the biggest conversations that I have had since 2017 have tended towards positivity. There are many opportunities for additional research and analysis if we were to dig into even just the Cool Dudes conversations. Some thoughts that I had while performing this research was pulling a larger data set: more years, understanding who is in the group at a given time to determine toxicity of individuals, and more.
This analysis was a fun extension of the network analysis from the last project. These individuals accounted for some of the largest nodes in that network and it is heartening to see that we may be a positive bunch.
References
Bing Liu, Minqing Hu and Junsheng Cheng. “Opinion Observer: Analyzing and Comparing Opinions on the Web.” Proceedings of the 14th International World Wide Web conference (WWW-2005), May 10-14, 2005, Chiba, Japan.