
Data mining PII via optical character recognition on publicly hosted image sites pt. 3

Data Collection & Methodologies
The data for this project was collected from https://prnt.sc using a Node.js script and the OCR package TextBoxes.
Data Collection
All screenshots taken using the Lightshot application are hosted at a public URL of the form
https://prnt.sc/******
where the trailing six characters are the unique identifier of the uploaded image. The string is alphanumeric, so there are 36^6 (2.1 billion) possible combinations. On the homepage, the site reports that there are just over 1.7 billion images that have been uploaded since 2010. This means that each URL generated by the script has approximately an 80.95% chance of being valid.
The random extension was generated using Javascript’s Math.random() function, which returns a pseudo-random floating point number between 0 and 1 and follows an approximately uniform distribution. It was discovered after the entire data set was collected that a combination of Math.round() and Math.random() used in generating these URLs could have broken the uniformity of the distribution of the random numbers. The impact of this may have resulted in a higher concentration of images from a certain period in time, but no noticeable impact was observed in the analysis.
Using the Puppeteer webdriver in headless mode, the script navigated to the generated URL in Chrome. Next, it checked for the existence of a web element in the page’s HTML. If an image existed at that location, it scraped the text and wrote an entry into a JSON file of the form:
{
url: <url>,
text: <scrapedData>
}
Example:
{
url:"https:/i.imgur.com/OLM2YOC.png",
text:"Welcome to my Facebook\r\n\r\n \r\n\f"
}
Note that the URL stored in the JSON object does not match what the script would have generated to access this image. It appears that the makers of Lightshot began to outsource their image hosting to the popular image hosting site Imgur at some point. When we navigate to one of the generated URLs and pull the image source from the HTML, it becomes clear that not all of the images are hosted in-house by the Lightshot team.
Early on, there were failures after ten calls were made. Since the failures happened after exactly ten calls each time, it pointed to potential request throttling. Changing the computer’s IP address allowed requests to go through to the site again. To circumvent this issue, a delay was added to the script. Although the delay allowed the requests to go through without the script failing, it significantly reduced the number of images that were scraped.
Some images were exceptionally large and could require up to 30 seconds to be analyzed. This was resolved by adding a maximum image buffer of 8192 * 8192. If an image exceeded that size, the script moved to the next image to save time.
The two final hurdles to gathering the initial raw data set were network related. A VPN put a minor delay on the process, but also helped ensure that the requesting IP address did not get blacklisted. The network had a very good uptime over the course of the two months of data collection, but if it went down overnight even for a minute, the script was unable to run again until it was manually restarted.
Under these environmental circumstances, an average of one image per 2.4 seconds was analyzed for about 40 days. The final data set consisted of 1,189,319 JSON objects, each consisting of a URL and a text blob at a total of 555.9 MB of data.
Data Preparation
The raw data was split across 12 JSON files of approximately 50 MB each. There was a lot of useless data, primarily from images that did not contain any text. The first step to clean up the data was to write another Node.js script to look for specific keywords and construct new JSON objects that only included data with matches.
There were no existing sets of “PII keywords” in a cursory Google search, so it needed to be built. The keyword list had 179 unique keywords, and is available at the end of this post in Appendix I. It consisted of keywords that fell into six primary categories: accounts, credentials, exploits, financial, other, and PII (Table 1). Most keywords fell into the financial category due to the wide variety of cryptocurrencies and their associated tickers. Any mention of Bitcoin or BTC were of interest, for example.

These keywords and their parent categories were saved in a JSON file with the intent to assign each matching data point to a category based on the matched keywords. That data was intended to be stored in six separate MongoDB tables and undergo analysis one category at a time. When the script was executed, it took the keywords and raw data JSON files as input and created an output JSON with objects in the form:
{
category: <category>,
url: <url>,
text: <scrapedData>
}
This was unsatisfactory for several reasons. First, it only added one piece of metadata to the raw data, so the main value that the script provided was simply filtering out entries that did not match the keyword list. Second, it pigeonholed the possibilities for analysis by forcing the relationship of any results to be associated with the category rather than the entire data set. There were several more issues with this approach including duplication of data across multiple categories, and fracturing the data across multiple tables in MongoDB.
After revisiting the goals of the project and further experimentation with MongoDB, the script was updated. Instead of categorizing the data based off of the keywords, it created an array of all of the keywords that were found in the text blob. Each result was also assigned an integer id. The format of the filtered JSON became:
{
id: <id>,
data:
{
matches: [keyword1, keyword2, ...],
url: <url>,
text: <scrapedData>
}
}
Example:
{
"id":1148,
"data":
{
"matches":["email"],
"url": "https:/image.prntscr.com/image/uFntpKl.png",
"text": "Videos\r\n\r\nEmail templates\r\n\r\n \r\n\r\nAttachments\r\n\r\nOa\r\n\r\n
\r\n\r\n \r\n\r\n \r\n\r\n07/22/2014at 8:34am\r\nDi\r\n\r\nJuly 21st 2014\r\n\r\n
\r\n\r\n \r\n\f"
}
}
The resulting dataset was loaded into MongoDB for preliminary analysis.
Data Analysis
The first round of analysis will highlight the frequency of the keywords among the text that contained matches. The second round of analysis will be to extract as large a quantity of usernames and passwords from the data set as possible. Finally, the Mongo database will be mined for additional data identified via the images analyzed in the second round of data analysis.
Data Analysis I
Since the raw data set was refined, some initial metrics needed to be gathered on the master data set. The master data set contained 236,726 data points, and including the new metadata, was 240.8 MB in size.
The first goal was to understand which keywords occurred the most frequently. Another Node.js script was developed to query the database and count the number of occurrences of each keyword. Results were written to a JSON file, and also captured in a CSV. There were 480,954 total keyword matches. 20 of the keywords did not result in any matches, and 73 of the words had at least 1000 occurrences.
One item of note was that none of the multi-word keywords returned any matches. This was almost certainly a shortcoming in the development of the keyword identification script. A potential for future analysis would be to refine the script or performing manual searches in MongoDB to get accurate results for these keyword sets.
A complete table of the keywords and their associated count is captured in Appendix I, and the 20 most frequently-occurring keywords are featured in Table 2 for discussion.
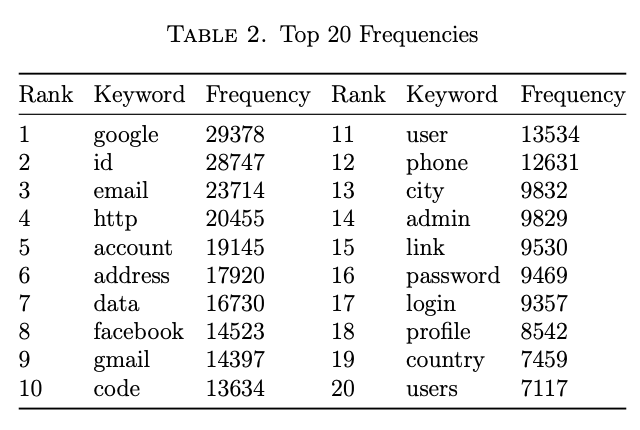
It was surprising that the word with the highest frequency was google when more common English words such as code and email were in the keywords list. The fact that google, facebook, and gmail are all in the top 10 most frequently appearing keywords is a demonstration of their worldwide presence. It also highlights a potential risk taken by the users of Lightshot. Since Gmail and Facebook are social networking sites, they contain personal information about their users. If screenshots of user accounts are being uploaded, then the effectiveness of privacy settings in those applications is reduced.
There were other surprises in the second set of twenty results. Paypal had 50% more occurrences (5,645) than amazon (3,909), but Hardwick at https://ahrefs.com notes that Amazon is ranked 5th for average monthly web traffic (492,468,801) while PayPal is 71st (21,064,326) in 2020. The massive discrepancy between keyword presence and monthly web traffic was a point of interest.
Some images then were analyzed for notable details. Gmail was selected as the keyword because it had undergone the most scrutiny up to this point in the research, and was the collection most familiar to the author. Ten URLs were selected from a partial MongoDB search result and viewed in a browser. Below are three of the results.
Figure 2

These are three emails sent to three different usernames with three new passwords. Note, however, that there are 52 emails in the inbox in every screenshot and that mark is signed in for at least two of them. Searching for jiratrade resulted in a single Google hit that stated the site no longer exists but was originally used to conduct financial scams.
One possibility is that this person hacked three accounts, set their email as the recovery address, and reset passwords. Another possibility is that someone was using these images as a honeypot to entice others that were consuming the images on prnt.sc to try the usernames and passwords themselves. This small sample of data raises the question of whether the data collected may contain a large number of honeypots or phishing attempts.
Recipients should be skeptical of any passwords sent via email. Doing so is a terrible security practice, and one that most legitimate enterprises avoid. Email can be subject to man in the middle attacks, in which an attacker intercepts packets in transit between sources. If the message is not encrypted, then that attacker can read or even alter the contents. A website created by security researcher Troy Hunt called Plain Text Offenders maintains a list of websites that send passwords in plain text. [The list]() contained 5764 offenders at the time of this writing.
Data Analysis II
The next portion of analysis was originally intended to pull as much personally identifiable information as possible from the collection of data. There proved to be too much PII in the set to be able to collect and aggregate it in a way that was easy to digest, so the goal pivoted to pulling strictly usernames and passwords. Since the data set was built from matches on keywords that were predicted to be correlated with sensitive personal data, this analysis could not be conducted using automated techniques.
The URLs for the top ten results were extracted from MongoDB, and for nine other keywords that were most likely to return user credentials (Table 3). These URLs were fed into text files delimited by new lines. A script was developed to loop through each line in each file and open up the URL in a browser and display for 5 seconds before moving on to the next line. Beginning with the smallest file and moving incrementally larger, a sample of 3,771 images was viewed and analyzed for usernames and passwords.
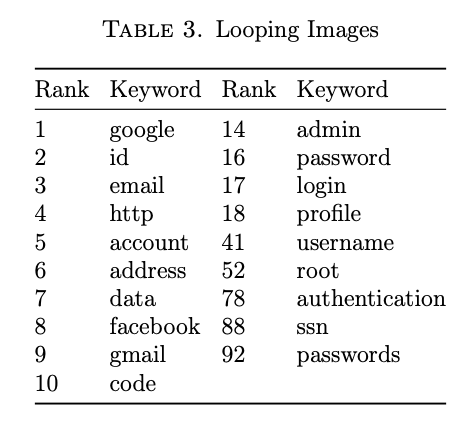
The top 10 ranked files all had over 13,000 entries which made actually viewing all of them time prohibitive. It would take just under 19 hours to view all of the results in the code file, which was ranked 10th and had 13,634 matches. Instead, focus was concentrated on the keywords most likely to be adjacent to actual username and password data.
Every image that contained a username and a password in the passwords, ssn, authentication, root files was noted, downloaded, and stored locally using another script.
Of the 3,771 images viewed, 105 contained at least one username and password or social security number. Some of those images contained lists of usernames and passwords for a website or for devices on a network.
Figure 3

Here we see the IP addresses and credentials for an administration panel as well as a website. A simple whois lookup can reveal many details about domain registration, administrator information, and potentially reveal insights into geographic locations of devices.
Figure 4

Manually reviewing the images that matched these keywords revealed some trends. Images hosted on the site that contain usernames and passwords generally fell into one of five categories:
- Plain text usernames and passwords displayed in an email (Figure 2).
- Usernames and passwords in a configuration document (Figure 3, Figure 5).
- Usernames and passwords in a list for account cracking (Figure 6).
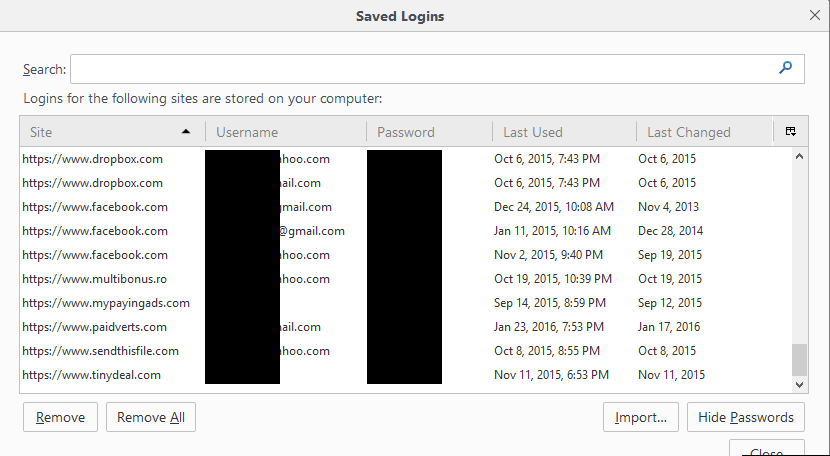
- Usernames and passwords in a browser password manager (Figure 7).
- Server or database configuration credentials in code (Figure 8).
During the first phase of analysis, it was observed that there were many similar plain text password email images. It is possible that most of the images that fell into that category were actually honeypots. Further analysis could be conducted to investigate whether there is a discernible ratio between true passwords and honeypots.
Configuration and on-boarding documentation for multiple companies were discovered, along with passwords for VPNs and on-premise storage repositories. These vendors were notified of the images.
Figure 5

It was surprising to see multiple lists of usernames and passwords listed within password cracking user interfaces. There were only four or five of these that appeared during the manual review, but each static image displayed 20 or more username and passwords for different users of a single site.
Figure 6
Browser password managers with un-obfuscated passwords for one person using multiple sites. These images corroborated the assertion that users often recycle passwords for multiple sites. Every one of the browser password manager screenshots included a password that was reused at least one time.
Figure 7
Credentials hard-coded into scripts was the second most prevalent variety of identified passwords. Not only did these betray poor coding practices by the authors, but database credentials can be the most destructive to have compromised because of the contents of their user tables.
Figure 8
Social security numbers were a unit of data that was of particular interest, but not affiliated with user credentials. This portion of the analysis included a search for those because of the potential identity damage that can be incurred by losing a social security number. It is not possible to directly measure the impact of a compromised SSN versus a compromised email account, but a leaked SSN is bad for its owner in every case. Figure 4 above contains many personal details about the individual, including SSN and passport details. The fact that there are social security numbers available on the site is a serious concern.
Data Analysis III
When the keyword frequency was measured, the script output the results to both a JSON and CSV file. The contents of the CSV file were originally going to be loaded into R to perform additional analysis and build visualizations. Each entry in the CSV file was of the form:
category, keywords, frequency
Experimentation with that data set did not produce very meaningful insights, especially as the focus shifted from full set analysis to username/password details. This was a critical blow to the intended analysis of the metadata of the set.
One of the original ideas for this portion of the analysis was to compare the prevalence of occurrences across the categories. That idea did not work, however, because the sets of keywords within each category were not actually comparable. In the financial category, for example, there were 63 unique keywords but the other category only had two. A demonstration that far more financial data was mined from this set than other data would not tell the intended story, if any story at all.
In the Limitations section of this paper, the dynamics of being able to gather more data or additional details about the collected data is addressed. This is one scenario where more metadata would have been great to have, but was not attainable due to time constraints.
Instead, the execution of two data analysis efforts were switched. Originally, looping through the images was to be the final piece of analysis, but after realizing that the R analysis would be fruitless it moved up in the order. After viewing thousands of images and saving the images that contained interesting data, the images containing credentials were reviewed and assessed for similarities or potentially interesting data. This ad-hoc visual metadata created a set of keywords and terms that were then used to search the data in the Mongo database (Table 4). For example, a search for “jiratrade” (from Data Analysis I) returned 916 results.
db.blob.find({"text": { $regex: "db_"}}).count()
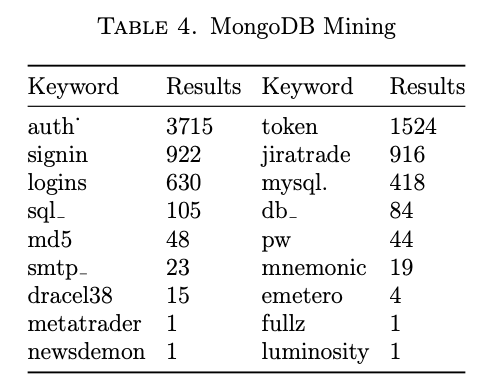
Assessment of the images that contained credentials resulted in another 18 keywords. The new keywords were chosen based on commonalities between images, such as the “jiratrade” emails. The other criteria that was used was searching for the name of password cracking applications. These searches were conducted against the full data set.
“Jiratrade” and “dracel38” were two phishing email or honeypot attempts, in which every single result was the in the same style and contained user credentials in plain text. The username and password in each email was unique in each of the \enquote{jiratrade} examples. The password and sender was unique in each of the \enquote{dracel38} examples. This means that the same image was not uploaded hundreds of times, but rather hundreds of nearly identical images.
The password cracking application keywords were completely unsuccessful, and only returned the original image again. “Logins” was another keyword that returned no credentials, even though there were 630 results.
Overall, another 26 usernames and passwords were mined from the new keyword images excluding the honeypots. Including the honeypots, 957 additional usernames and passwords were mined using the keywords that were pulled from other images.
Limitations
The data gathering phase took an extraordinary amount of time due to the rate limits imposed by the prnt.sc site. Increasing the analysis rate to 2.4 seconds per image created multiple constraints.
It limited the size of the data set. Given the final scope of the project, 1.18 million data points was sufficient for analysis but it was less than one one-thousandth of the total possible data pool. Since the collected data set is such a small portion of the whole, it puts a lot more importance on the randomization of the URL generator in the script to get a true random sample.
Rate limits also determined that the set collected was immutable. During the initial analysis of the data set, a series of questions came to mind that could have been answered through metadata. If the script had pulled details about the date the image was uploaded, for example, some time-based analysis could have been performed. Since it would take another two months to collect the same quantity of data including the additional details of interest, it was simply not an option (this could have been avoided by doing an early assessment before all of the data was collected).
Another limitation was the keyword set which was used to filter the data after collection. These keywords were not based on statistical inference of any data, but were keywords that seemed to have good potential for revealing compromising data. Since there are millions of words in the data set, a single additional keyword could open the door to an entirely new set of images for analysis.
The trustworthiness of the image hosting source was the largest limitation. Image hosting sites usually contain verbiage in their terms of service that limit what a user is allowed to upload; however, that is primarily to protect the host. For example, Lightshot’s terms of service prohibits users from uploading:
- Pornography, adult or mature content. This includes, but is not limited to, files depicting genitalia, nudity, or sexual situations.
- Files that are illegal and/or are in violation of any United States laws.
- Any other content that is illegal, promotes illegal activity or infringes on the legal rights of others.
The terms of service also state:
We are not responsible for the content of any uploaded files, nor is it in affiliation with any entities that may be represented in the uploaded files. We direct full legal responsibility of files to their respective users. All other content is copyright by Skillbrains.
Facebook and other social media sites use machine learning to analyze images that are being uploaded for pornographic content and prevent users from uploading them entirely. There is also accountability on many sites because users are often required to create an account before they can upload content. Lightshot, however, “do[es] not require you to use an account to upload images. We do not share, sell, or even show anyone your name, email or profile information.”
Since there is no guarantee that users of the application cannot upload illegal content, it is unsafe to indiscriminately download images from any website that allows user uploads. The latest United States Code of law states that possession of child pornography is punishable by up to 10 years in federal prison (18 U.S.C. § 2251).
As a result, none of the images were downloaded during data collection. The ability to perform local analyses on such a large image set would have opened up many more opportunities, but those opportunities were absolutely not worth the risks.
Finally, there was insufficient time to build a machine learning algorithm to train on images that contained usernames and passwords in cleartext. It does create an opportunity for future research, though it would be prudent to build a larger set of true positives for the training set prior to doing so.
Stay tuned for the next post, containing the results…
Appendix I